Presentation posted on Oct 7, 2020
Motivation
Traditionally, R2R controllers handle the disturbances in processes to be controlled using partitions, or control threads, which basically are unique combinations of certain context attributes, e.g., machine, product, layer, etc. Each partition is controlled separately using data only from that partition itself. This is because, with proper definition of the partitions, disturbances can be separated into different partitions so that the variability within each partition should be much smaller than the overall variability. Ideally, variability within each partition can be further reduced with more specific partition definition, however, the amount of data that is available to each partition is also reduced by adding more context attributes into the partition criteria. Over-definition of partitions can lead to large number of partitions and data poverty. This problem is especially severe in the high-mix manufacturing environment like foundries. For example, it may be difficult to keep some low-running products updated if they require their own partitions. There are several ways to handle this problem. For example, similar partitions (e.g., reticles) can be combined into a partition group that share data with each other. A controllers can be designed flexible enough to allow partition criteria change or even support hierarchical partitions definition so that the controller can start with the most specific partition and switch dynamically to partitions with relaxed criteria if not enough data is found. One can simulate the controller with large number of datasets to find the best partitioning scheme. The controller can also track the time and number of wafers/runs since a partition was last tuned and use control-oriented dispatching to help ensure that partition will be updated and request a pilot if the last tuning was too long ago. However, it is still beneficial to find the optimal partition criteria for the controller to start with, in order to achieve its full potential with the additional functionalities added later.
Approach
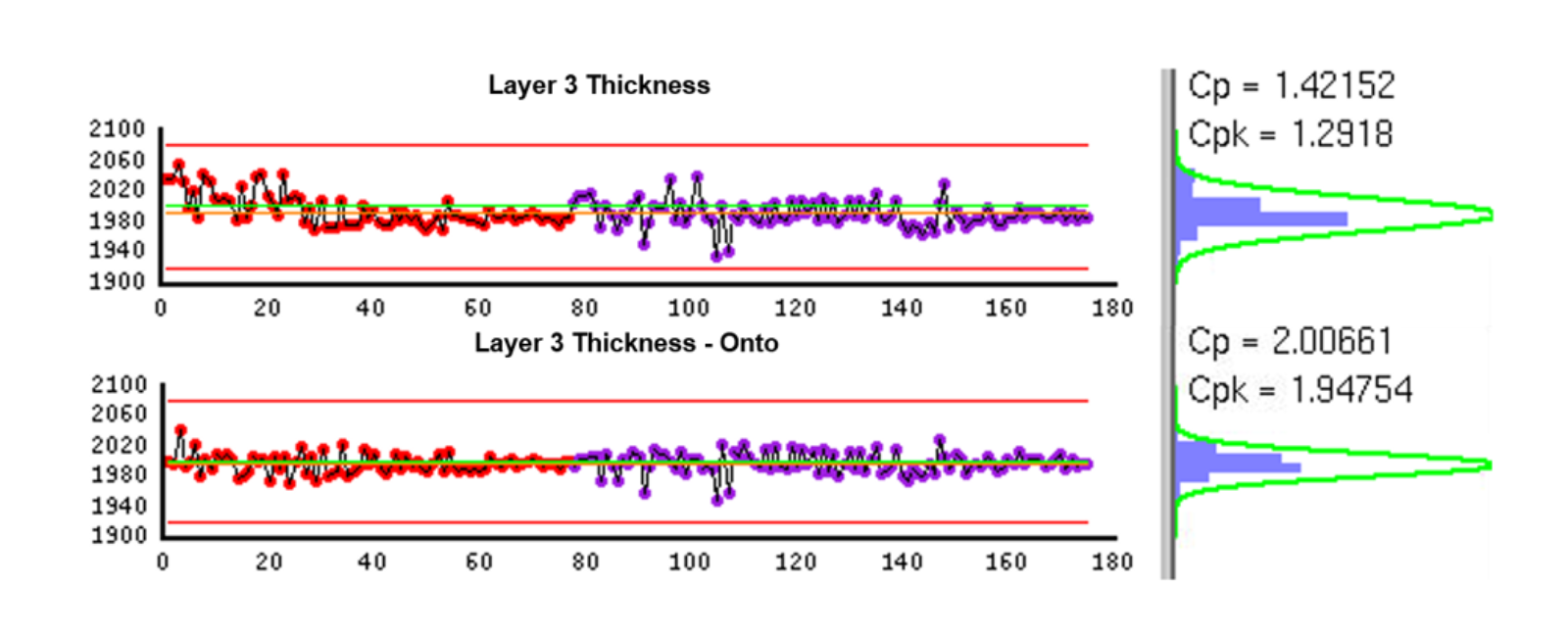
Motivated by these considerations, this paper presents a case study of finding the optimal partition criteria for a CVD control strategy that we built with Discover Run-to-Run and deployed at a customer site. A CVD control strategy typically maintains a linear process model of layer thickness vs. process time which is used to calculate the process time setting for each lot at runtime that supposedly will result in the desired target layer thickness value. The actual layer thickness of this lot is later measured on a metrology equipment and fed back to the controller to update the process model. Also, an exponentially weighted moving average (EWMA) filter is typically used to remove the high frequency noise before the model update is done. In design of the CVD control strategy, we first partitioned it by tool and layer. This is because different tools typically behave differently and therefore cannot share data with others. Meanwhile, we observed stratified deposition rate by layer, which indicates data from different layers should also be separated. The CVD controller partitioned by tool and layer was then simulated with 2 months of production data and the results predicted a 15% total Cpk improvement on layer thickness. We were also told that different products could introduce variabilities in the process due to the differences in patterns built on them. Therefore, we simulated the same data with different partition criteria which require a unique control loop also by product. Although the simulation results showed an additional 13% increase in the total Cpk, the process owner raised concern about data poverty for some low-running products. To have a closer look at sources of the CVD process variabilities, we employed the data analytics tool, Discover Yield. We did a quick ANOVA analysis for the dep rate data and the results confirmed significant dep rate variability in tool and layer but less in product. The fact that the dep rate variability in product is not significant suggests the controller should remain partitioned by tool and layer. However, we can still manage this smaller disturbance by creating constant offsets by product in the CVD controller. In this way, different products share data with each other but still maintain their differences.
Results
As a result, the new controller design guided by the data analytics showed an additional 8% Cpk improvement on average, even superior to the one partitioned by tool, layer and product (Fig. 5). Also, the current thickness data is skewed and R2R will drive it back to the target. The next step would be to automate the ANOVA analysis in Discover Yield, recalculate the dep rate offsets by product periodically, and feed the most recent offset data to the CVD controller. More results on this matter will be shared in the presentation.